Research interests
My research centers on developing advanced machine learning techniques to solve urgent open challenges in biology and ecology. For example, I have developed biodiversity monitoring models that integrate Earth observation data (satellite imagery, aerial photography), citizen-science wildlife observations and geospatial datasets. In 2025 we published a perspective article detailing how machine learning can dramatically scale up protected area monitoring using these data sources.
I work with a wide range of machine learning techniques, ranging from Bayesian inference to LLMs. I enjoy writing code a lot, and still get excited when models learn to perform a task well. More specifically, I have a strong interest in AI methods that extract efficient features from high-dimensional data and simultaneously minimise data requirements, such as self-supervised, weakly supervised and unsupervised learning. Our brains are phenomenal in doing so – we take in a constant stream of sensory information and rarely get explicit feedback – and therefore continue to inspire me.
Career highlights include mapping the entire Peak District National Park at 12.5 cm resolution — the first updated land cover map in 40 years, building a probabilistic model of the entire zebrafish brain (100k neurons), and adapting techniques from neuroscience and representation learning to interpret geospatial embeddings. I’m also passionate about reproducible code, promoting open-access science (e.g., as an associate editor for ESE), and contributing to open-source software. If this interests you, I have written a Python tutorial on reproducible figure making for scientists.
My big vision: an AI system that combines multimodal biodiversity data to transparently monitor the condition of habitats at scale. I think it’s one of the most exciting ML and scientific challenges out there right now, requiring the right mix of foundation models, messy data, and expert knowledge. I currently lead the development of a VLM-based model that language-aligns geospatial embeddings to make explainable predictions of species distributions, but this is just the first step! If you’re interested in what’s next, check out my 2025 position paper or let’s talk!
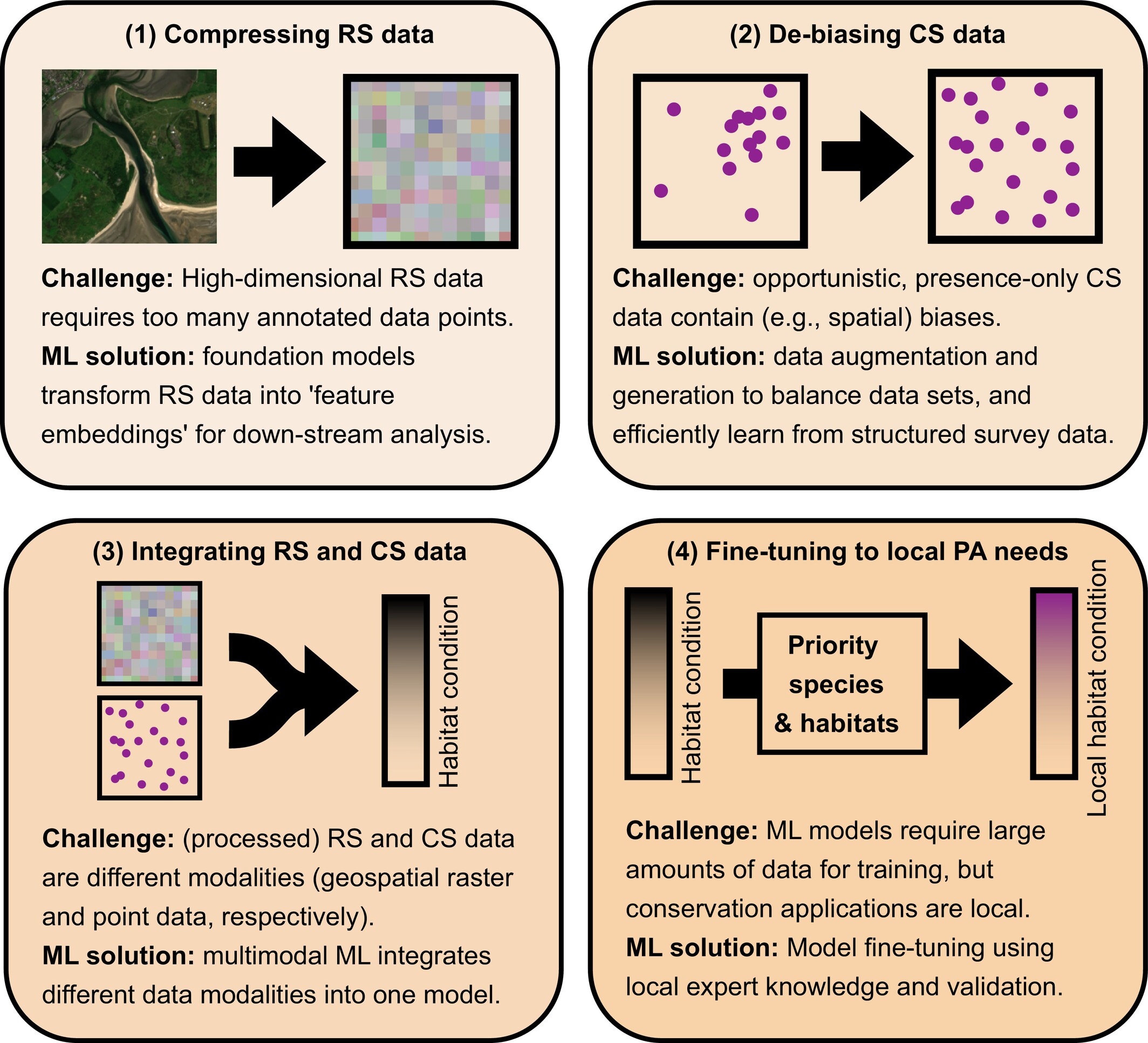
Figure from Van der Plas et al., 2025, Ecol. Sol. Evid.